The Data Analytics Platform
A 100% open source, integrated framework that accelerates application development for data analytics
The team behind CDAP
- Ajai Narayanan
- Albert Shau
- Ali Anwar
- Andreas Neumann
- Bhooshan Mogal
- Derek Wood
- Edwin Elia
- Jay Jin
- Lea Cuniberti-Duran
- Nitin Motgi
- Poorna Chandra
- Rohit Sinha
- Sagar Kapare
- Sreevatsan Raman
- Terence Yim
- Tony Hajdari
- Vinisha Shah
- Yaojie Feng

Cloud Data Fusion launched on GCP
Cloud Data Fusion is a fully managed, cloud-native, enterprise data integration service, powered by CDAP, for quickly building and managing data pipelines on Google Cloud Platform. Visit the Google Cloud Console to try it out today.
Visit Google Cloud ConsoleWhy CDAP
CDAP lets developers, business analysts and data scientists focus on insights, analytics and business value instead of wrestling with infrastructure, and integration.
Reduced complexity
Increased velocity
Increased flexibility
Improved visibility
CDAP features
Rapid development
Developer SDK and APIs with abstractions over common data processing patterns; Sandbox mode, programmatic and UI driven debugging; In-memory mode and testing framework to simplify testing; Support for cutting edge Cloud, Apache Hadoop and Apache Spark technologies.
HideEnterprise ready
Metadata repository with automatic technical and operational metadata capture; Business metadata annotations; Data discovery through search based on metadata; Data governance with dataset and field level lineage and auditing; Integration with enterprise security systems.
HideSeamless operations
REST APIs and CLI for every interaction; Time and process based scheduling; Standardized logs and metrics for all execution environments.
HidePortable runtime environments
Build once, run anywhere through portability across runtime environments such as Apache Hadoop YARN and Docker.
HideExtensible and reusable
Templates and blueprints for common use-cases; Hub for sharing pre-built plugins, applications and solutions; Extensible APIs for security, metadata, runtimes and storage.
HideHybrid and multi-cloud
Interoperability across on-premises and Cloud environments; Support for all major public cloud providers such as Amazon Web Services, Microsoft Azure and Google Cloud Platform.
HideAccelerators
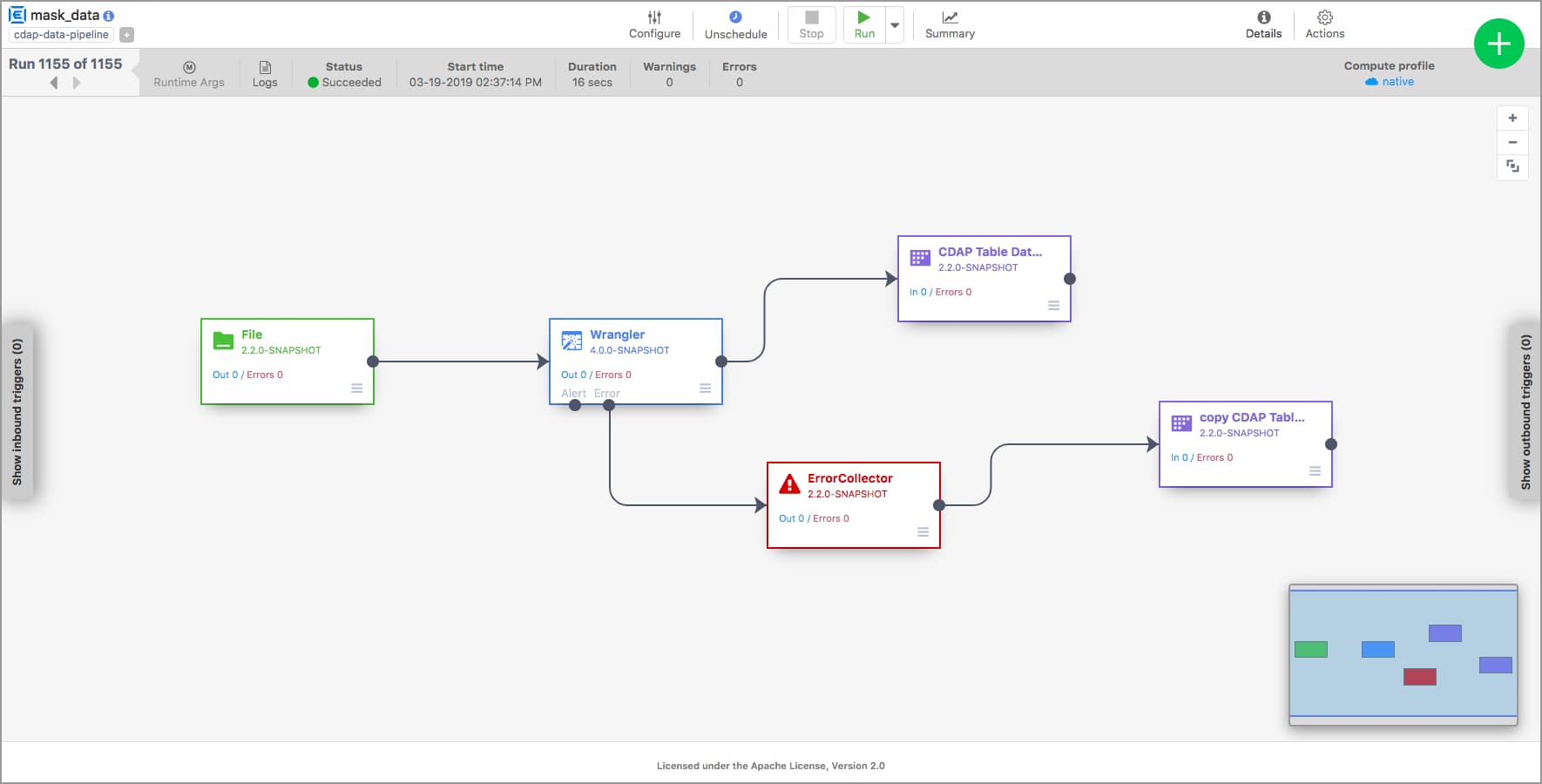
Pipelines
Pipelines provides an easy-to-use graphical data integration interface to bring together data from a myriad of different sources and define transformations visually.
Learn more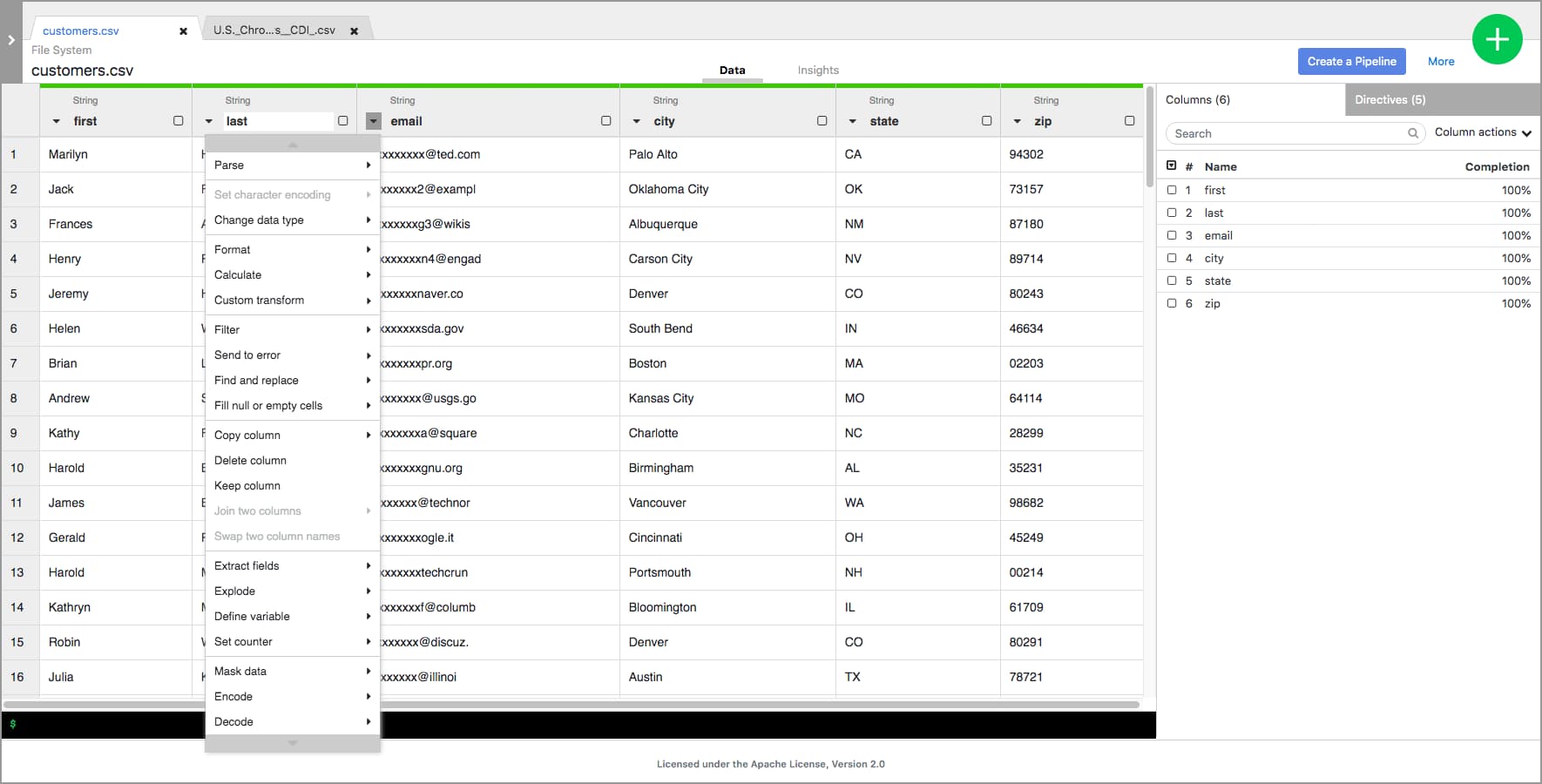
Wrangler
Wrangler allows you to visually and interactively cleanse and prepare raw data, with the aim of making it consumable for further processing. It provides a standardized UI driven interactive flow that takes the pain out of preprocessing tasks for data engineering, data science and data analysis. Learn More
Learn more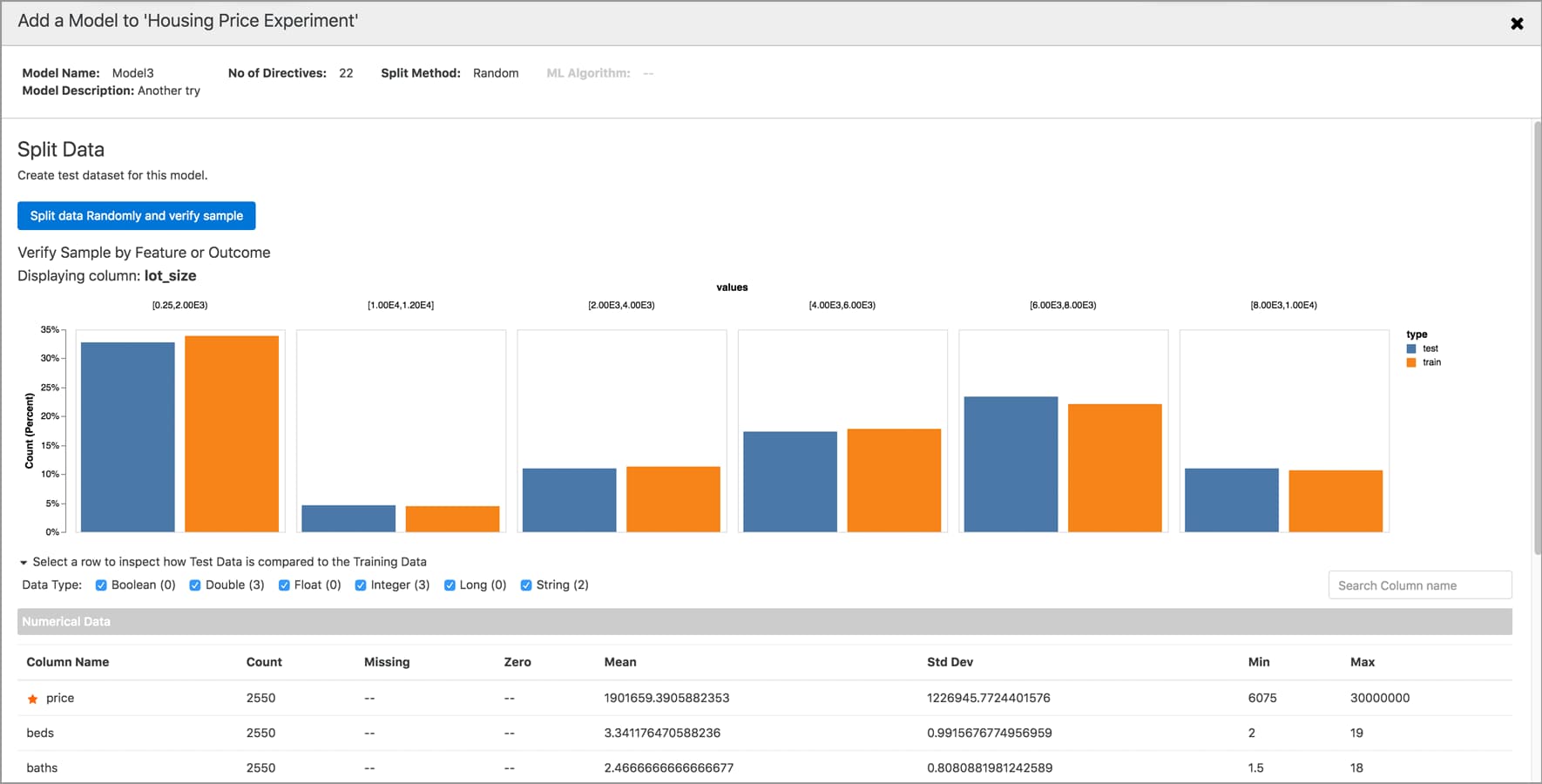
Analytics
Analytics provides a simple, interactive, automated interface for users to easily develop, train, test, evaluate and deploy their machine learning models.
Learn more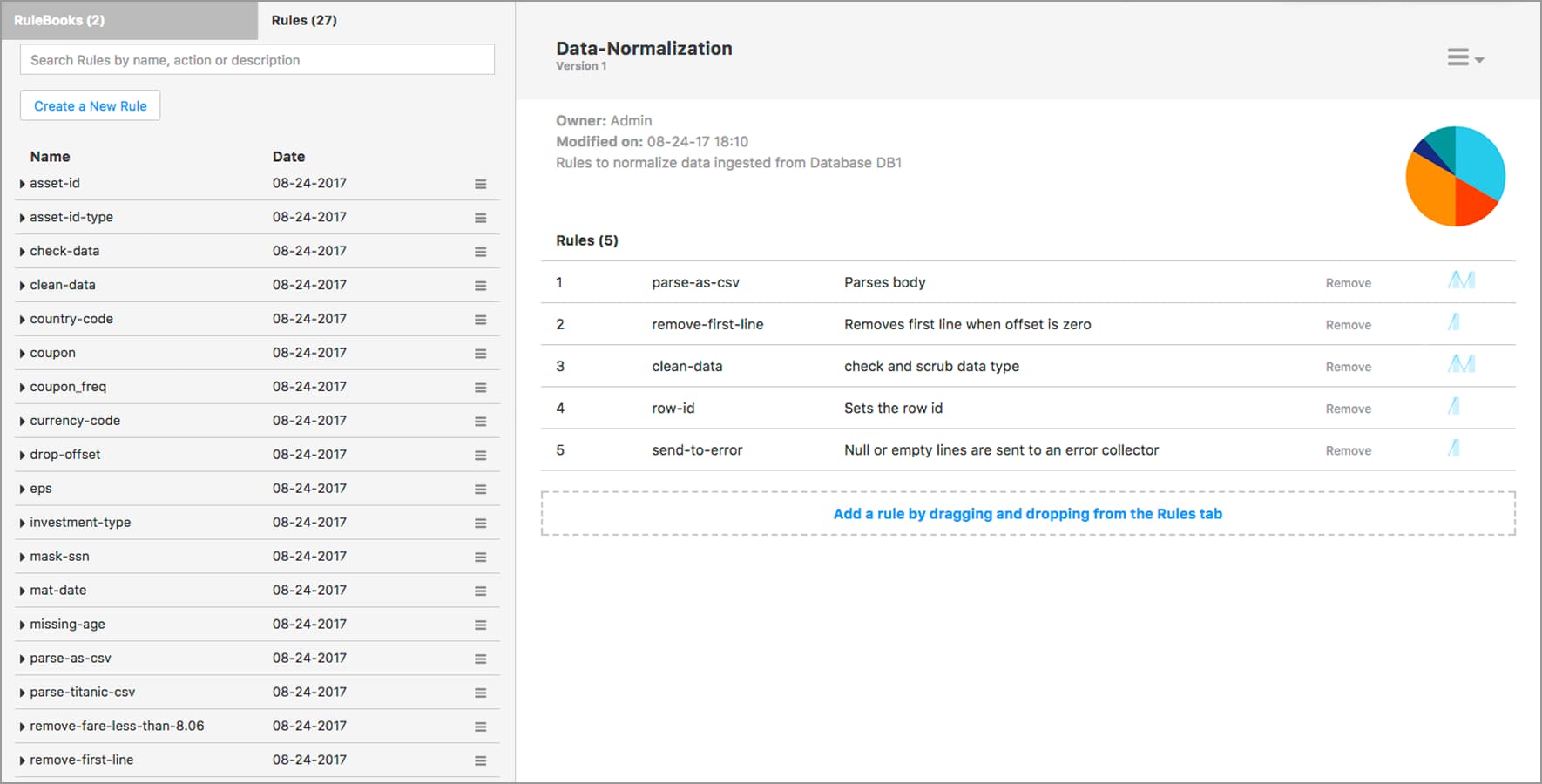
Rules
Rules Engine provides a way for business analysts to create and manage a knowledge base of data transformation rules that need to be automatically applied to your data.
Learn morePartners
